I will show you two plots side by side. Figure 1 shows the Google Trends graph for interest in AI, and Figure 2 shows the stock chart on NVIDIA's website.
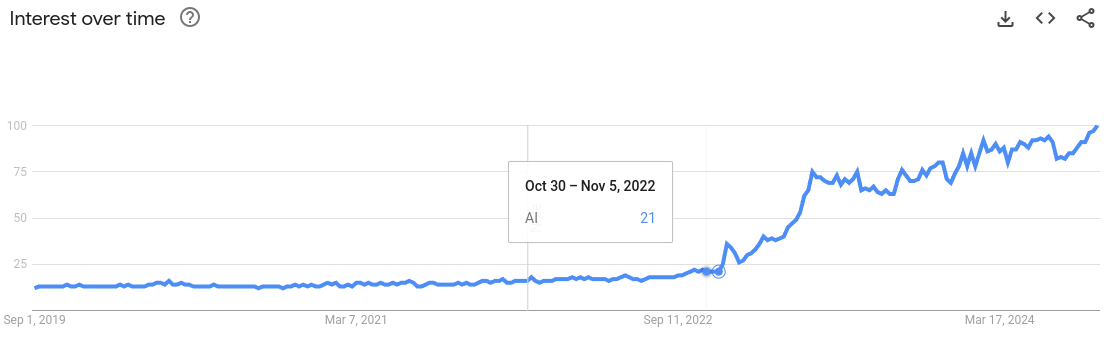
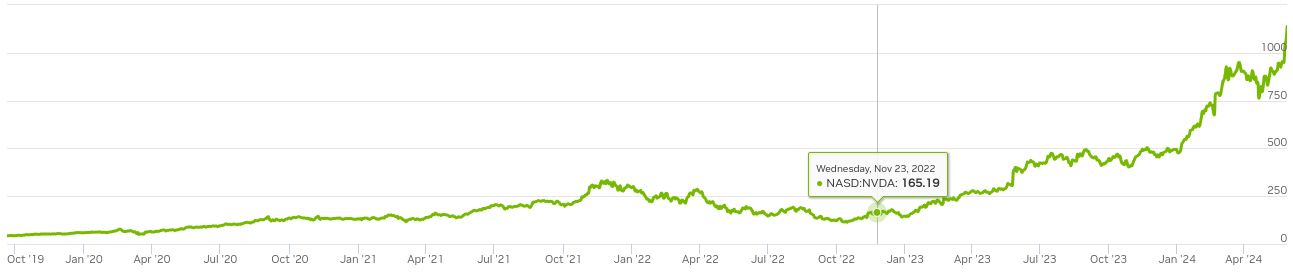
It is no coincidence that as the interest in AI rose, so did the NVIDIA stock value. In the last 10 years or so, the field of AI has been dominated by algorithms using neural networks at their heart. And, at the heart of neural nets, there's matrix multiplication. Over 90% of the neural net's compute cost comes from several matrix multiplications done one after the other [1].
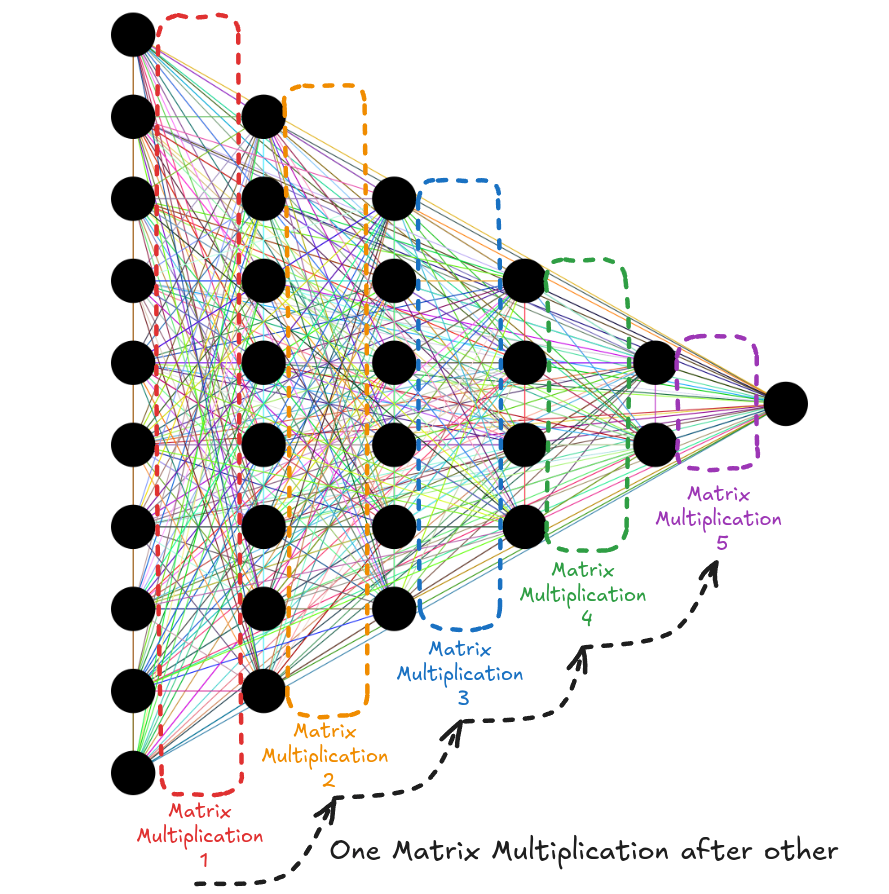
But why does NVIDIA benefit from this? Anyone can do matrix multiplication. I can write it myself in under 15 lines of C++ code.
void matrix_multiplication(float *A_mat, float *B_mat, float *C_mat, int n)
{
for (int row = 0; row < n; row++)
{
for (int col = 0; col < n; col++)
{
float val = 0.0f;
for (int k = 0; k < n; k++)
{
val += A_mat[row*n + k] * B_mat[k*n + col];
}
C_mat[row*n + col] = val;
}
}
}Matrix Multiplication involving square matrices of size n x n
Even better, I can use an open-source library like Eigen.
#include <Eigen/Dense>
int main(int argc, char const *argv[])
{
// .
// .
// .
// Generate Eigen square matrices A, B and C
// .
// .
// .
// Perform matrix multiplication: C = A * B
C_eigen = A_eigen * B_eigen;
// .
// .
// .
return 0;
}Matrix Multiplication using Eigen
However, when performing matrix multiplication on large matrices, which is common in modern neural networks, the computational time becomes prohibitively long. The duration of a single matrix multiplication operation can be so extensive that it becomes impractical to build large neural networks using these libraries.
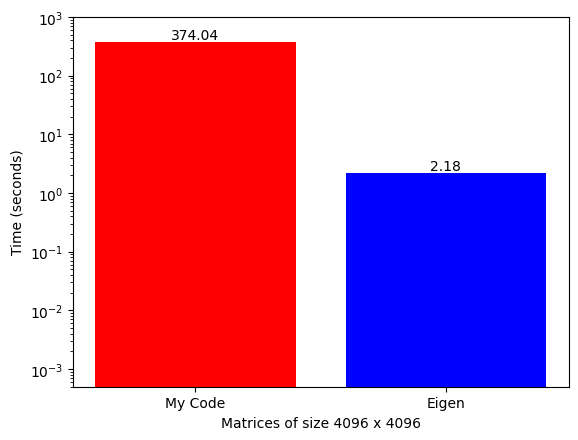
Where NVIDIA shines is that it has developed a GPU-accelerated library called cuBLAS (that runs only on NVIDIA GPUs) and has a function called SGeMM (Single Precision General Matrix Multiplication) that can do the same thing extremely fast.
#include <cublas_v2.h>
int main(int argc, char const *argv[])
{
// .
// .
// .
// Generate square matrices d_A, d_B and d_C
// .
// .
// .
// Perform matrix multiplication: d_C = alpha*(d_A * d_B) + beta*d_C
float alpha = 1;
float beta = 0;
cublasSgemm(handle,
CUBLAS_OP_N, CUBLAS_OP_N,
n, n, n, // Num Cols of C, Num rows of C, Shared dim of A and B
&alpha,
d_B, n, // Num cols of B
d_A, n, // Num cols of A
&beta,
d_C, n // Num cols of C
);
// .
// .
// .
return 0;
}Matrix Multiplication using cuBLAS
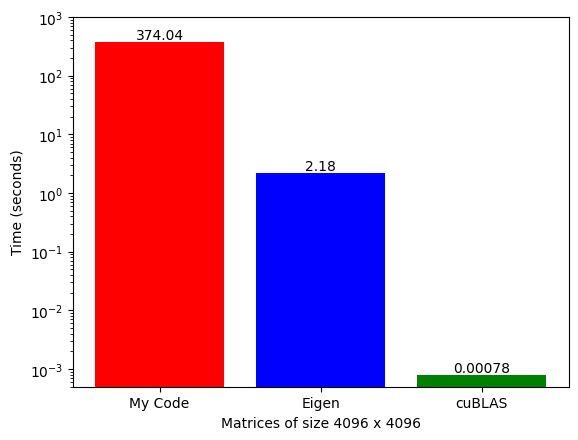
NVIDIA GPUs are the main reason for this speed-up. Whenever we write standard code in high-level programming languages like C++, by default, it runs sequentially on the CPU. We can exploit some level of parallelism from CPUs (that's what Eigen does), but GPUs are built specifically for parallel computing. NVIDIA provides CUDA (Compute Unified Device Architecture), allowing software to use GPUs for accelerated general-purpose processing.
My goal with this mini project is to code general matrix multiplication from scratch in CUDA C++ and (try to) get as close as possible to the cuBLAS SGEMM implementation. I will do this step by step (keeping the code base as simple as possible) and, along the way, discuss:
- CUDA API functions and how to use them.
- NVIDIA GPU hardware, including CUDA cores and various memory units.
- Several parallel GPU programming concepts like:
- Global memory coalescing
- 2D block tiling
- 1D and 2D thread tiling
- Vectorized memory accesses
xGeMM
There are a total of 6 blog posts covering this mini-project. Check out the page linked below for more details.

References
- Code repository
- Blog post by Simon Boehm