
So far I have not been able get any meaningful improvement over the naive GPU implementation of 2D convolution (table below shows runtime). I will first start with the detailed analysis of the runtime and try to see what the bottlenecks are.
| GPU (Naive) | GPU (Constant Memory only) | GPU (Constant Memory + Tiling) | |
|---|---|---|---|
| Total execution time (seconds) | 0.00944 | 0.00916 | 0.00939 |
Running any application on a GPU involves four broad steps:
- Allocating GPU memory
- Transferring data from CPU memory (RAM) to GPU global memory (VRAM).
- Performing calculations using the GPU cores.
- Transferring results from GPU global memory (VRAM) to CPU memory (RAM).
The table below shows the detailed breakdown of the runtime the application.
| GPU (Naive) | GPU (Constant Memory only) | GPU (Constant Memory + Tiling) | |
|---|---|---|---|
| Memory Allocation time (seconds) | 0.000108 | 0.000262 | 0.000228 |
| CPU to GPU Transfer time (seconds) | 0.00327 | 0.00302 | 0.00298 |
| Kernel execution time (seconds) | 4.606e-05 | 5.824e-05 | 5.750e-05 |
| GPU to CPU Transfer time (seconds) | 0.00602 | 0.00582 | 0.00611 |
| Total execution time (seconds) | 0.00944 | 0.00916 | 0.00939 |
It is clear that data transfer to and from GPU is the major bottleneck! It is around two orders of magnitude slower than the kernel execution and if I have to decrease the overall runtime, I must reduce the data transfer speeds. There is an easy way to do that, but I want to first understand why isn't kernel runtime improvement with the use of constant memory and shared memory?
Caches
Figure 3.1 shows the physical view of the GPU hardware. The GPU is organized into an array of highly threaded streaming multiprocessors (SMs). Each SM has several processing units called streaming processors or CUDA cores (shown as green tiles inside SMs) that share control logic. The SMs also contain a different on-chip memory shared amongst the CUDA cores inside the SM (known as shared memory). GPU also has a much larger (and slower) off-chip memory, the main component of which is the global memory or VRAM.
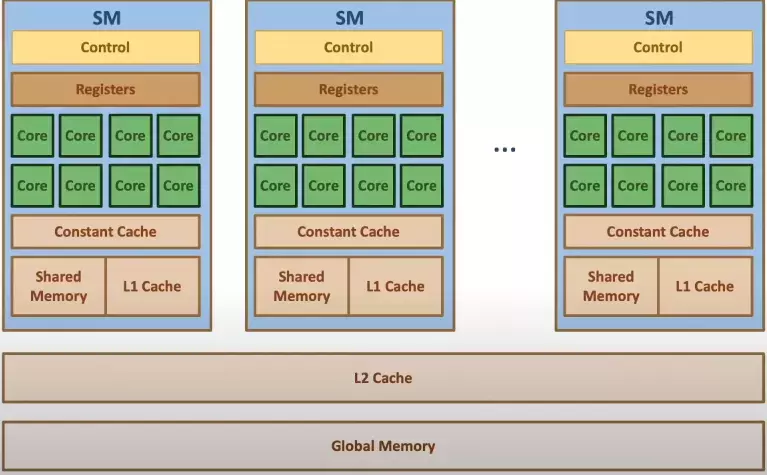
To mitigate the effect of long latency and low bandwidth of global memory, modern processors employ cache memories. Unlike the CUDA shared memory, caches are transparent to programs. This means that the program simply accesses the global memory variables, but the hardware automatically retains the most recently or frequently used variables in the cache. Whenever the same variable is accessed later, it will be served from cache, hence eliminating the need to access VRAM.
Due to the trade-off between the size and the speed of a memory, modern processors often employ multiple levels of caches (as shown in Figure 3.1). L1 cache runs at the speed close to that of the processor (but it’s very small in size). L2 cache is relatively large but takes tens of cycles to access. They are typically shared among multiple processor cores or SMs in a CUDA device, so the access bandwidth is shared among SMs.
Looking at my 2D convolution code, there are two things that stand out:
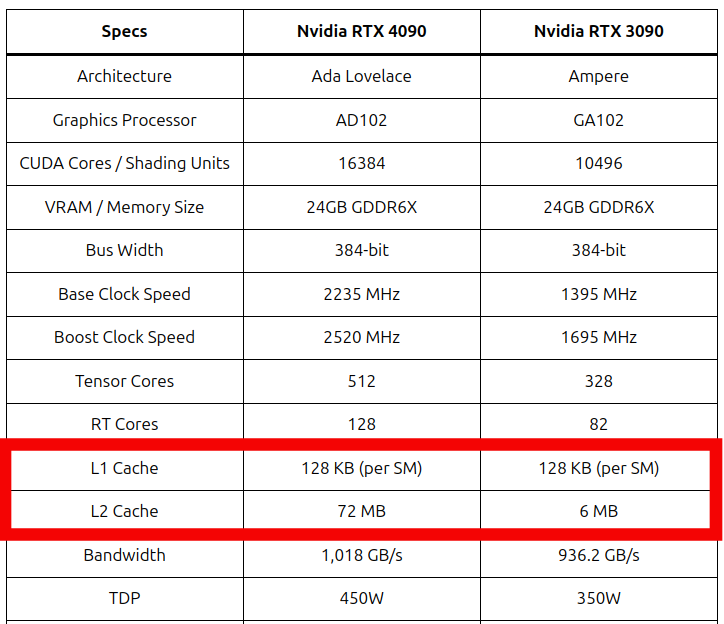
- Input image is relatively small (\(2048 \times 2048\) pixels) and the filter is even smaller (\(3 \times 3\)): Modern NVIDIA GPUs have large enough caches (see Figure 3.2) to fit a large chunk of the data, such that global memory accesses are reduced automatically.
- To compute one output element, I'm performing 9 multiplications and 9 additions: There is an overhead related to the data transfer when using constant or shared memory. The idea behind using these memory units is that the performance loss can be compensated by much faster calculations, and as there aren't that many calculations to perform, there is no significant improvement.
With this out of the way, I can finally move on to reducing the CPU to GPU (and vice-versa) data transfer times.
Pinned Memory
Modern computing systems can be viewed by a physical or logical perspective. Just like GPUs, where on the physical level we have SMs, CUDA cores, caches, etc. Programmers rarely even interact with hardware directly. Instead, they use logical constructs like threads, blocks and grid to interface with the actual hardware.
Similarly with the CPU memory (RAM), there are two perspectives:
- Physical Memory: This represents the actual memory cells installed on the motherboard like RAM.
- Virtual Memory: This is an abstract concept that makes it easy for the programmer to manage memory. It is created by operating system and CPU maps the logical memory to physical address in RAM.
By default, CPU allocated memory is paced physically in RAM and logically in pageable memory. The issue with pageable memory is that the data can be swapped automatically between RAM and other slower memory units like HDD (to keep RAM free for other processes). This means that when I try to transfer the data from CPU to GPU, it might not be readily available on the RAM! To mitigate this, I can use pinned memory. Data in the pinned memory cannot be moved away from the RAM and will 100% be there whenever data transfer is required.
Using pinned memory is very easy. CUDA provides an API function cudaMallocHost() that allocates the pinned memory. The only thing I have to do is use this function for allocating the host memory and rest of the program stays exactly the same. Figure 3.3 shows an example where I use pinned memory for input and output images.
int main(int argc, char const *argv[])
{
// Allocate pinned memory for the images (input and output)
float* N;
err = cudaMallocHost((void**)&N, 2048*2048*sizeof(float));
cuda_check(err);
float *P;
err = cudaMallocHost((void**)&P, 2048*2048*sizeof(float));
cuda_check(err);
// .
// .
// .
}Figure 3.3: Using pinned memory.
Benchmarking
The table below shows the detailed benchmarks for the naive GPU implementation using pageable and pinned memory.
| GPU (Naive) using Pageable Memory | GPU (Naive) using Pinned Memory | |
|---|---|---|
| Memory Allocation time (seconds) | 0.000108 | 0.000217 |
| CPU to GPU Transfer time (seconds) | 0.00327 | 0.00265 |
| Kernel execution time (seconds) | 4.606e-05 | 4.507e-05 |
| GPU to CPU Transfer time (seconds) | 0.00602 | 0.00249 |
| Total execution time (seconds) | 0.00944 | 0.00542 |
Using pinned memory, the runtime is almost halved! This is a decent uplift because now the application runs at around 184 FPS compared to 105 FPS when pageable memory was used.
Application Demo
For the final application, I decided to use pinned memory on the CPU side and constant memory on the GPU side. I'm not using shared memory via tiling as I don't want to complicate my codebase for negligible performance uplift (if that).
I've used Makefile to make compilation (and execution) easy. All I have to do is run a simple command make filters_gpu, and it will automatically compile the source code and run the executable. This will prompt an input from the use to type in the filter of choice (see Figure 3.4).
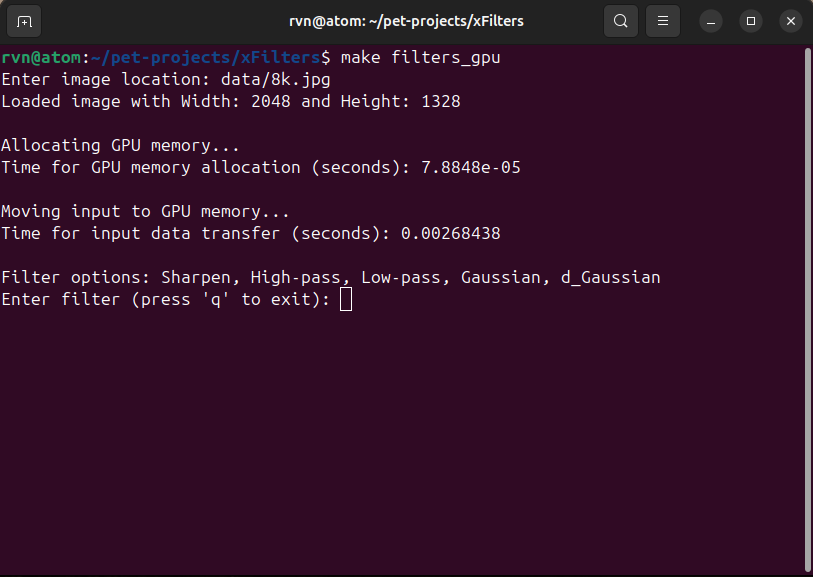
Let's say I decided to use the Sharpen filter. In this case, it will ask me to enter the sharpen strength (between 0 and 1), and I decided to use 0.8. After this, the program will apply the filter to the supplied image and store back the output image on the disk. All the information including detailed benchmarks will be displayed in the terminal (see Figure 3.5). Figure 3.6 shows the original image alongside the filtered image.
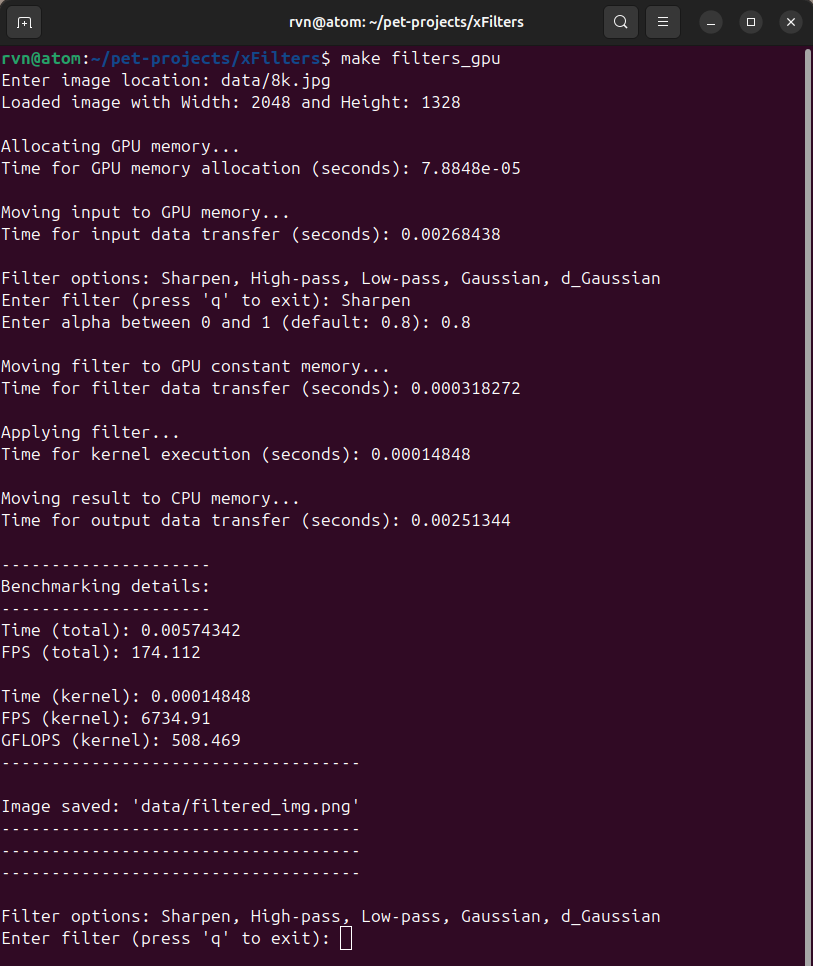

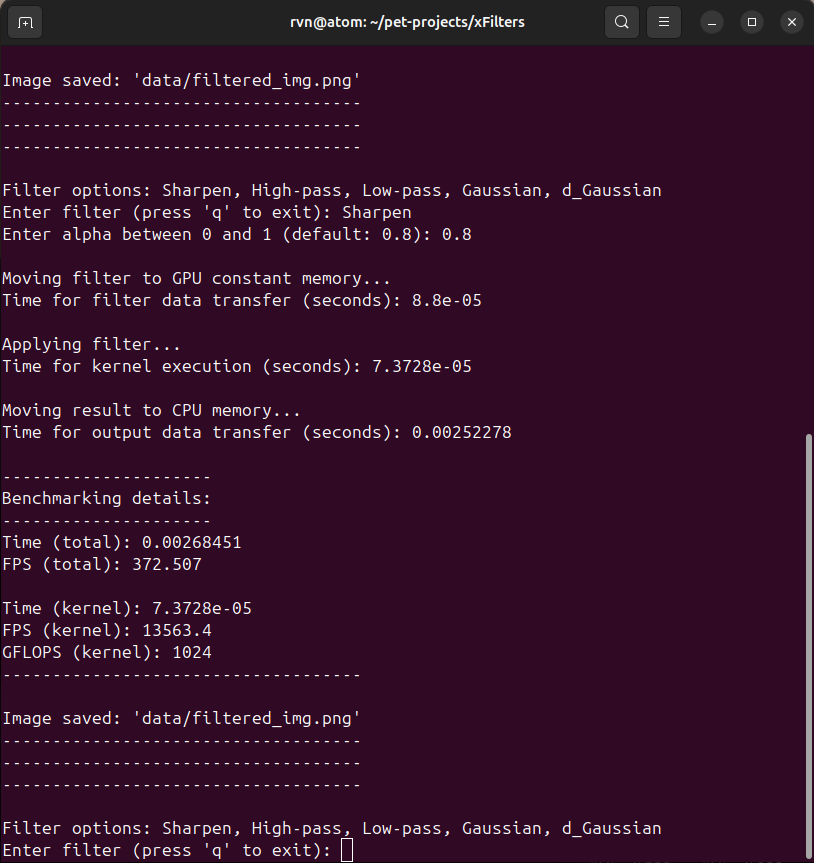
I've written this code keeping in mind that the user can try multiple filters on the same image. I want the application to reuse the image that is already in the GPU global memory (as that is a bottleneck), and this results in the 2nd run being much faster. Figure 3.6 shows that the total FPS now is over 372 (compared to 174 in Figure 3.5).
Conclusion
I explored several topics in this mini project and the summary is as follows:
- 2D convolution can be accelerated significantly using a GPU.
- When the application is computationally light (relatively), using specialized memory units like constant or shared memory might not result in a significant improvement.
- using pinned memory can significantly accelerate the data transfer between CPU and GPU memory.
References
- Kirk, David B., and W. Hwu Wen-Mei. Programming massively parallel processors: a hands-on approach. Morgan kaufmann, 2016.
- Ansorge, Richard. Programming in parallel with CUDA: a practical guide. Cambridge University Press, 2022.
- Memory types in GPU by CisMine Ng.
- Pinned Memory by CisMine Ng.
- Stack Overflow: Shouldn't be 3x3 convolution much faster on GPU (OpenCL)
