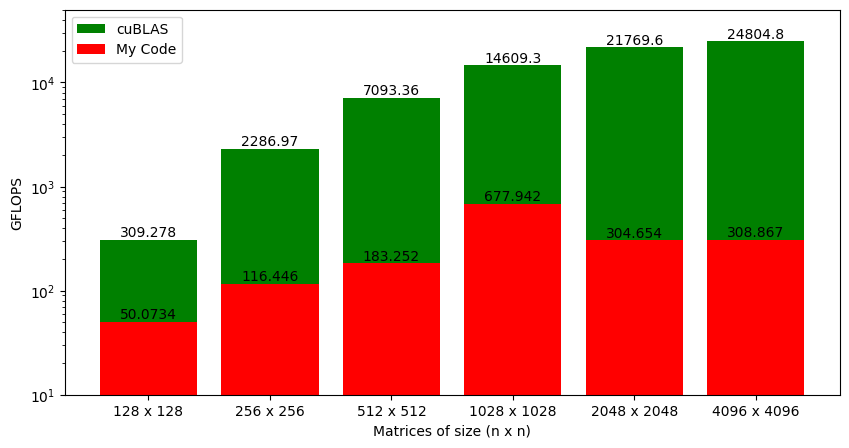
Looking at the GFLOPS from our kernel function and cuBLAS SGEMM (Figure 1), there are two main questions:
- Why are GFLOPS increasing with matrix sizes?
- How can we improve the performance of our kernel function?
To answer these questions we need to understand the GPU hardware better.
Modern GPU Architecture
Figure 2 shows a high-level CUDA C programmer's view of a CUDA-capable GPU's architecture. There are four key features in this architecture:
- The GPU is organized into an array of highly threaded streaming multiprocessors (SMs).
- Each SM has several processing units called streaming processors or CUDA cores (shown as green tiles inside SMs) that share control logic.
- The SMs also contain a different on-chip memory shared amongst the CUDA cores inside the SM.
- GPU also has a much larger off-chip memory, the main component of which is the global memory or VRAM.
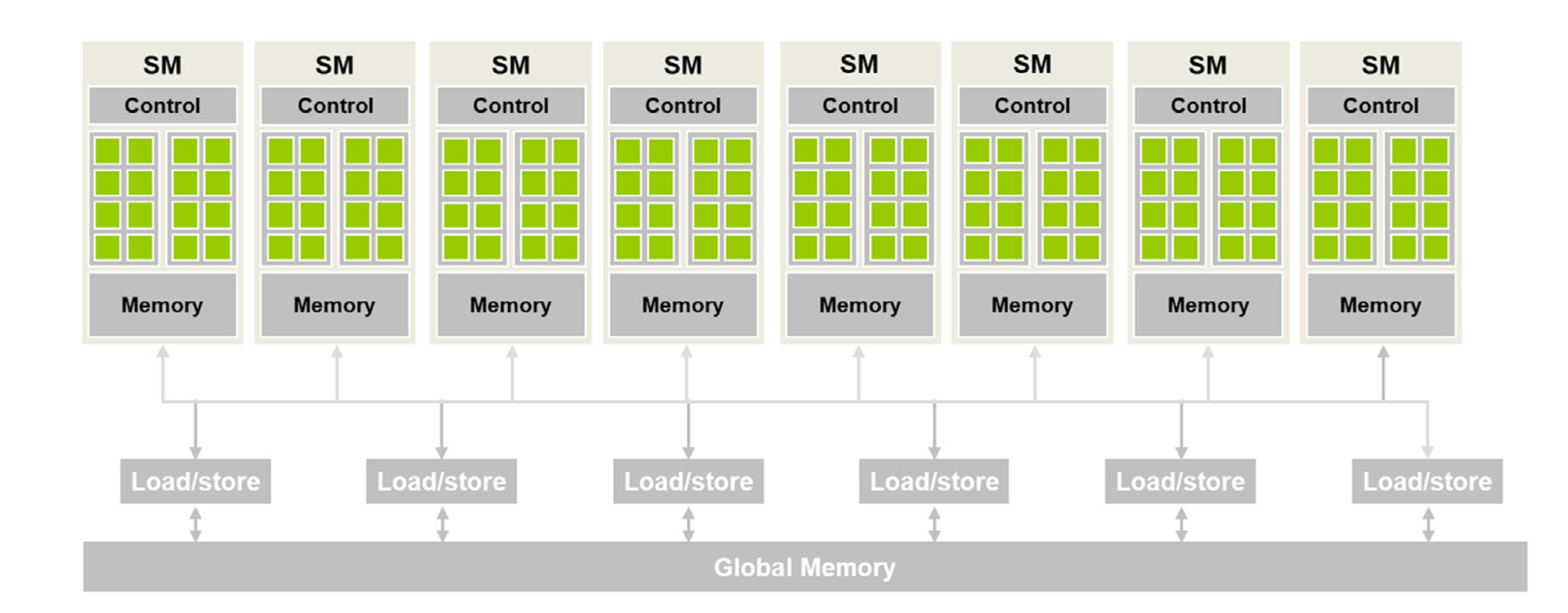
There are two main takeaways from Figure 2:
- CUDA cores in different SMs can't interact with each other or access memory from other SMs.
- As the global memory is off-chip (i.e., some distance away from the cores), it has long latency and low bandwidth.
Thread Blocks and SMs
When a kernel is called, the CUDA runtime system launches a grid of threads that execute the same kernel code. These threads are assigned to SMs on a block-by-block basis, i.e., all threads in a block are simultaneously assigned to the same SM. For the matrix multiplication example, multiple blocks will likely get simultaneously assigned to the same SM.
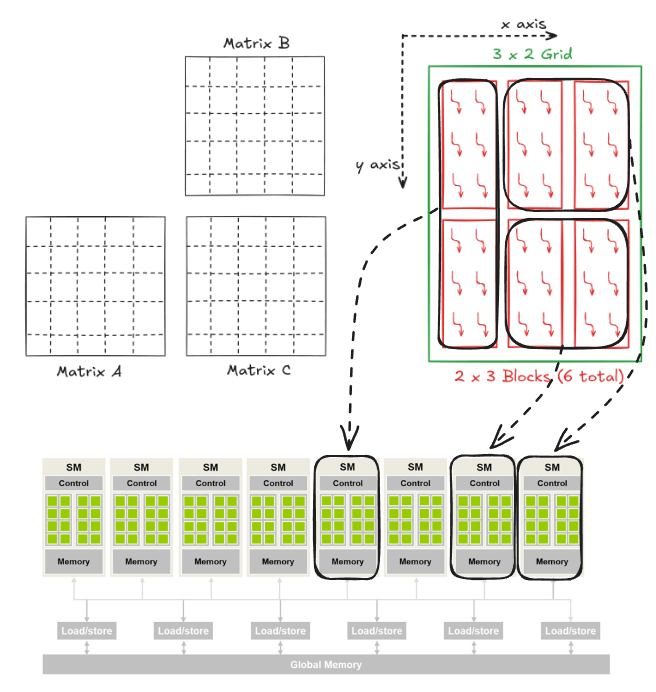
The example discussed in Figure 3 is quite small. In real-world problems, there are a lot more blocks, and to ensure that all blocks get executed, the runtime system maintains a list of blocks that did not get assigned to any SM and assigns these new blocks to SMs when previously assigned blocks complete execution. This block-by-block assignment of threads guarantees that threads in the same block are executed simultaneously on the same SM, which makes interaction between threads in the same block possible.
For a moment, it might look like an odd choice not to let threads in different blocks interact with each other. However, this feature allows different blocks to run independently in any order, resulting in transparent scalability where the same code can run on different hardware with different execution resources. This, in turn, reduces the burden on software developers and ensures that with new generations of hardware, the application will speed up consistently without errors.
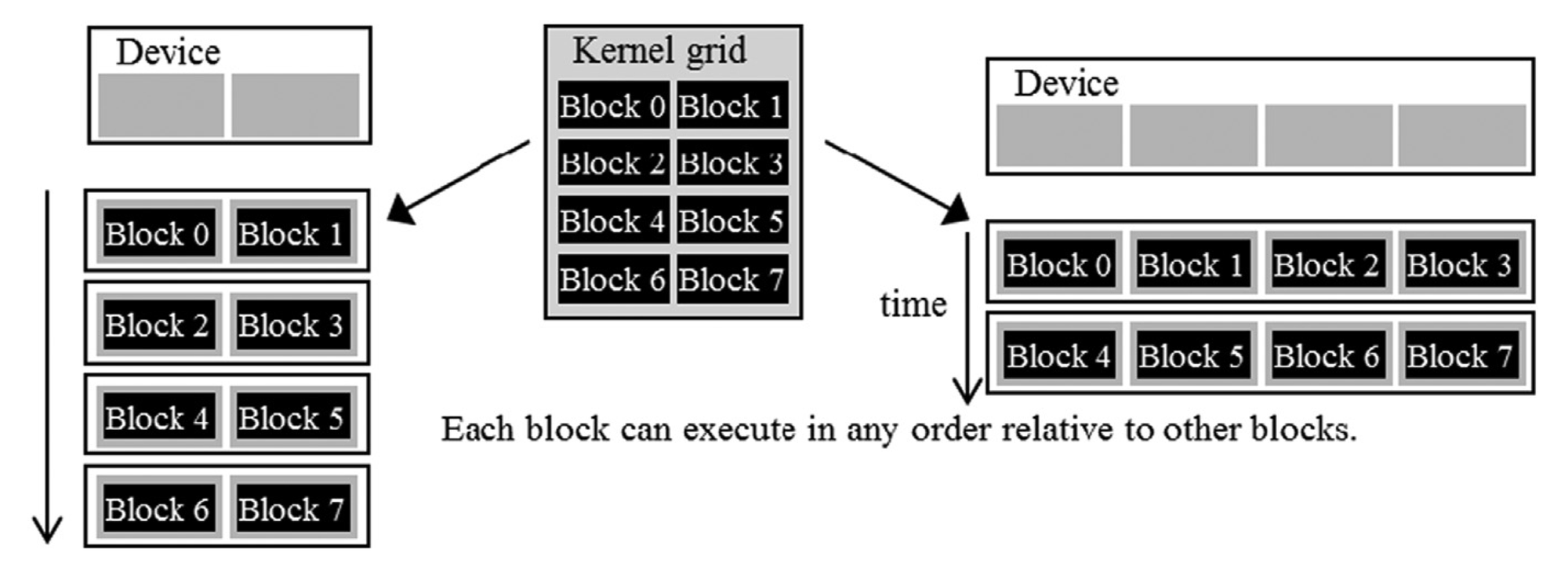
Warps
In the previous section, I explained that blocks can execute in any order relative to each other, but I did not say anything about how threads inside each block are executed. Conceptually, the programmer should assume that threads in a block can execute in any order, and the correctness of the algorithm should not depend on the order in which threads are executed.
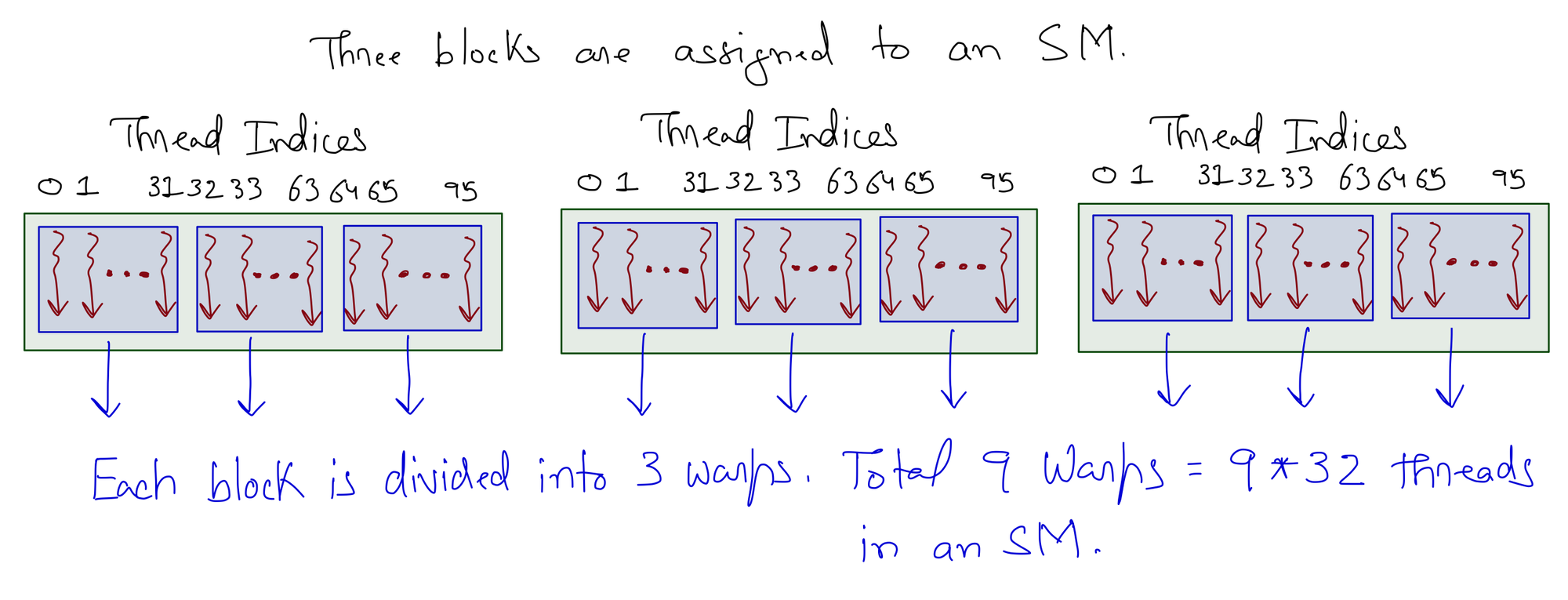
Thread scheduling in CUDA GPUs is a hardware implementation concept that varies depending on the type of hardware used. In most implementations, once a block is assigned to an SM, it is divided into 32-thread units called warps. The knowledge of warps is useful for understanding and optimizing the performance of CUDA applications.
Each warp consists of 32 consecutive threads. For 1D block, this is straightforward such that threadIdx.x is used to divide the threads into warps.
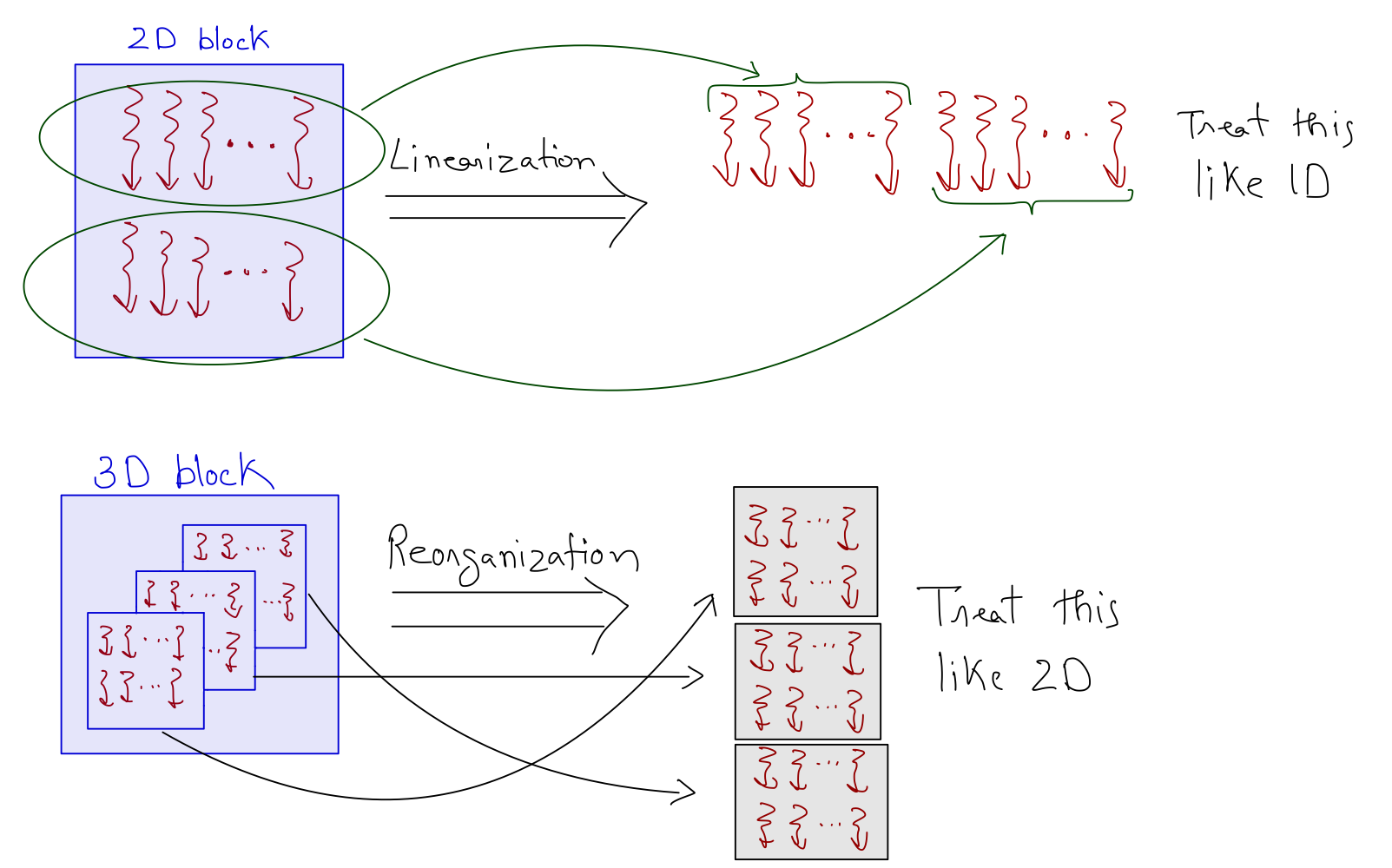
For the 2D block, threads are linearized using a row-major layout and partitioned into warps like the 1D case. For the 3D block, the z dimension is folded into the y dimension, and the resulting thread layout is treated as the 2D case.
An SM is designed to execute all threads in a warp following the SIMD model, i.e., at any instance in time, one instruction is fetched and executed for all threads in the warp. As one instruction is shared across multiple execution units, it allows for a small percentage of the hardware to be dedicated to control, and a large percentage is dedicated to increasing the arithmetic throughput (i.e., cores).
Kernel Function
There are three main steps to the running a program on the GPU:
- Copy data from host memory to device global memory.
- Perform computations using the device cores and the data stored in device global memory.
- Copy results from device global memory to host memory.
We can't do much about steps 1 and 3 as we have to move data between host and device memory. To be honest this is computationally intensive but again, it's a one time thing and with large data, we can offset the cost with gains from solving the problem in parallel. So my focus here is to analyze the kernel function.
As a recap, the algorithm for parallel matrix multiplication involving matrix A of size (M x K) and B of size (K x N) is as follows:
- \(M \cdot N\) threads are generated on the GPU (one to compute each element of matrix \(C\) which is of size M x N).
- Each thread:
- Retrieves a row of matrix \(A\) and a column of matrix \(B\) from the device memory. This results in the total of 2 x 4K Bytes being copied from device global memory.
- Loops over the elements.
- Multiplies the two numbers and add the result to the total, which is stored back in the device global memory. This results in the total of 4 Bytes being copied to device memory.
For all M x N threads, we are accessing M x N x (2 x 4K + 4) Bytes. If we have 4096 x 4096 matrices, the accesses from device global memory amount to 512 GB! I'm focusing so much on these memory accesses because global memory has long latency and low bandwidth, which is usually a major bottleneck for most applications.
Answering the Questions
Why GFLOPS increase with increasing Matrix Size?
From the knowledge of the GPU hardware (that we have acquired so far), it looks like the loss in performance for matrix multiplication with small matrix sizes (Figure 1) is mostly due to the global memory accesses. However, this does not explain why GFLOPS increase with the increase in the matrix size. I mean that with large matrices, the number of global memory accesses also increases, but the counter intuitively, the performance increases as well! GPUs can do this because the hardware is capable of latency tolerance or latency hiding.
There are usually more threads assigned to an SM than its cores. This is done so that GPUs can tolerate long-latency operations (like global memory accesses). With enough warps, SM can find a warp to execute while others are waiting for long-latency operations (like getting data from global memory). Filling the latency time of operations from some threads with work from others is called latency tolerance or latency hiding. The selection of warps ready for execution does not introduce any computational cost because GPU hardware is designed to facilitate zero-overhead thread scheduling.
That's why, for large matrices, more warps are available to hide the latency due to global memory accesses. There is a limit (set by CUDA) to the number of warps that can be assigned to an SM. However, it's not possible to assign an SM with the maximum number of warps that it supports because of constraints on execution resources (like on-chip memory) in an SM. The resources are dynamically partitioned such that SMs can execute many blocks with few threads or a few blocks with many threads.
For example, an Ampere A100 GPU can support 32 blocks per SM, 64 warps (2048 threads) per SM, and 1024 threads per block
So, if
- A grid is launched with 1024 threads in a block (maximum allowed)
Ans. Each SM can accommodate 2 blocks (with 2048 threads total, matching the maximum allowed per SM).
- A grid is launched with 512 threads in a block
Ans. Each SM can accommodate 4 blocks (with 2048 threads total, matching the maximum allowed per SM).
- A grid is launched with 256 threads in a block
Ans. Each SM can accommodate 8 blocks (with 2048 threads total, matching the maximum allowed per SM).
- A grid is launched with 64 threads in a block
Ans. Each SM can accommodate 32 blocks (with 2048 threads total, matching the maximum allowed per SM).
A negative situation might arise when the maximum number of threads allowed per block is not divisible by the block size. For example, we know that an Ampere A100 GPU can support 2048 threads per SM
So, if
- A grid is launched with 700 threads in a block
Ans. SM can hold only 2 blocks (totaling 1400 threads), and the remaining 648 thread slots are not utilized. The occupancy in this case is 1400 (assigned threads) / 2048 (maximum threads) = 68.35%.
How to improve Kernel Performance?
For large matrices, there will be enough threads assigned to each SM such that the hardware can get around the issue of global memory latency. To improve the kernel performance, we must makes efficiently accessing data from global memory a top priority.
To effectively utilize the global memory bandwidth, we must understand a few things about the architecture of the global memory. Global memory in CUDA devices is implemented using DRAM (Dynamic Random Access Memory) technology, which usually takes tens of nanoseconds to access a data byte. This starkly contrasts modern computing devices where the access speed is sub-nanosecond per byte. As the DRAM access speed is relatively slow, parallelism is used to increase the rate of data access (also known as memory access throughput).
Each time a DRAM location is accessed, a range of consecutive locations are also accessed in parallel. These consecutive location accesses and delivery are known as DRAM bursts. Current CUDA devices employ a technique that takes advantage of the fact that threads in a warp execute the same instruction at any given time. When all threads in a warp execute a load instruction, the hardware detects whether the memory accesses are consecutive or not. If they are consecutive, a lot of data can be transferred in parallel faster. In short, all threads in a warp must access consecutive global memory locations for optimum performance (this is known as coalesced access).
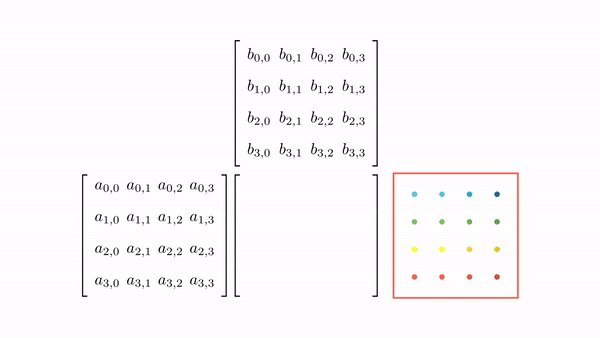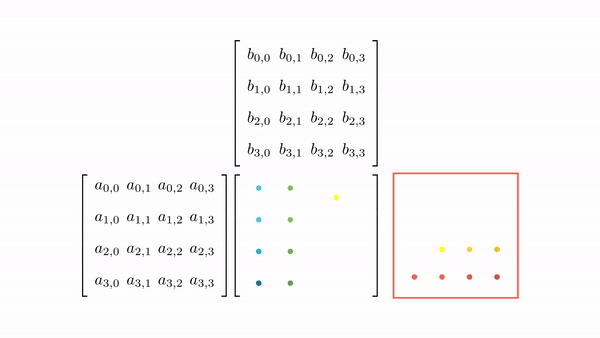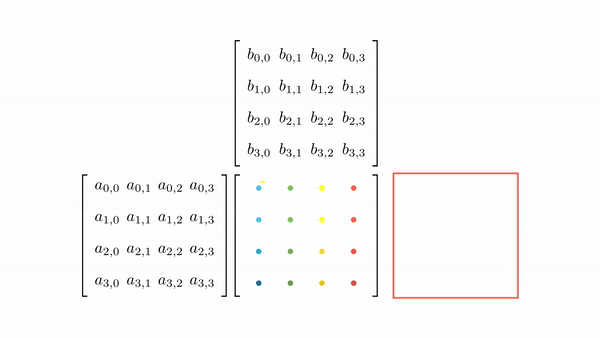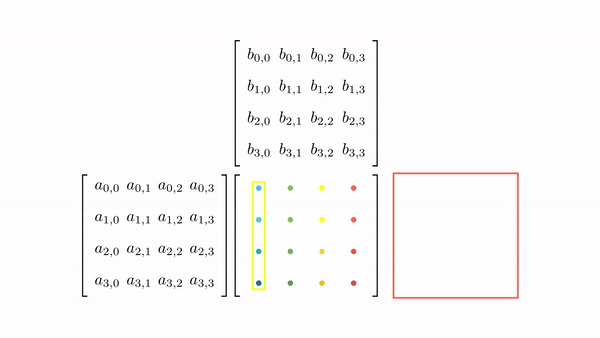
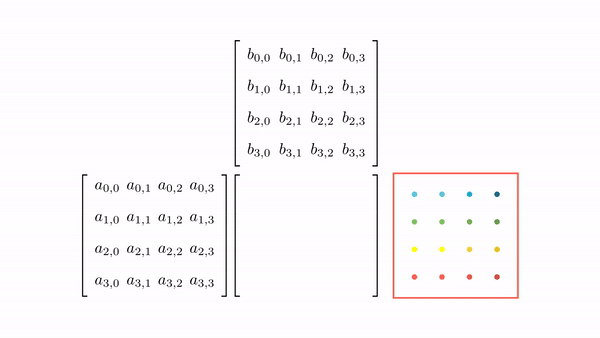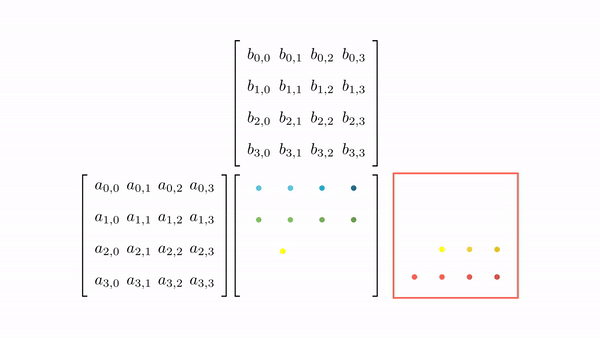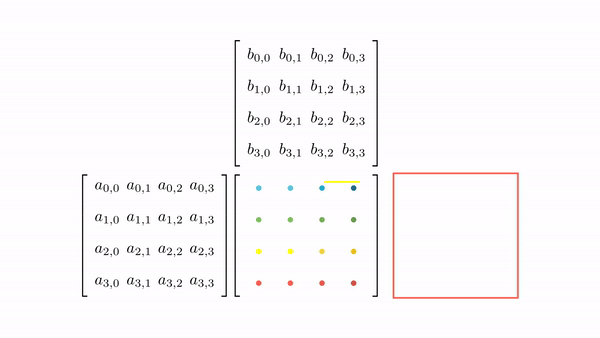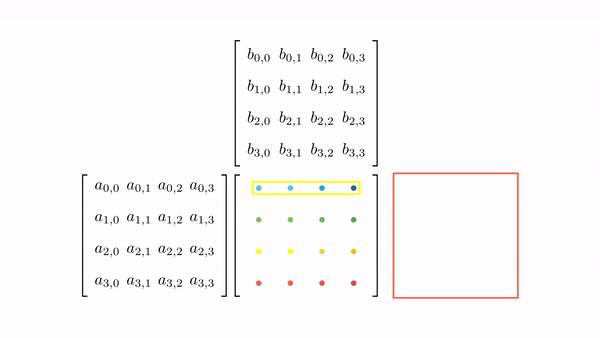
Figure 7 shows the pictorial analysis of the thread to element mapping. It's worth noting that the consecutive threads the warp are mapped to the columns of the output matrix. This means that each thread accesses the same column of matrix B and consecutive rows of matrix A. For any iteration k, threads in this warp access the elements of matrix A, which are N elements apart in the memory (remember that the 2D matrix is stored in a row-major layout in memory). As the threads in a warp are not accessing the consecutive elements in the memory, DRAM can not transfer these in parallel, hence requiring a separate load cycle for each element (Figure 8)!
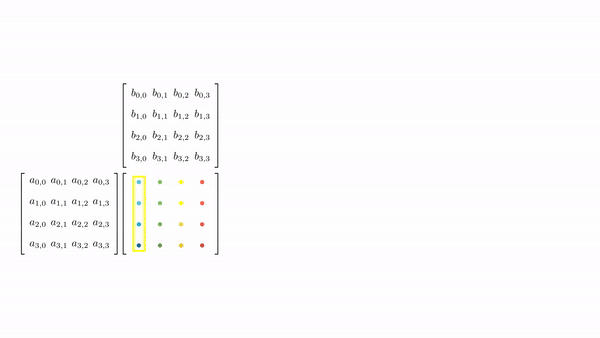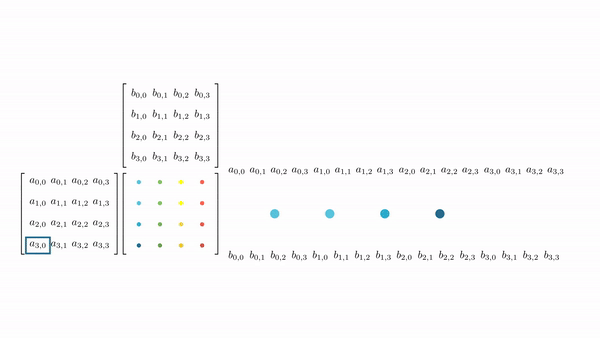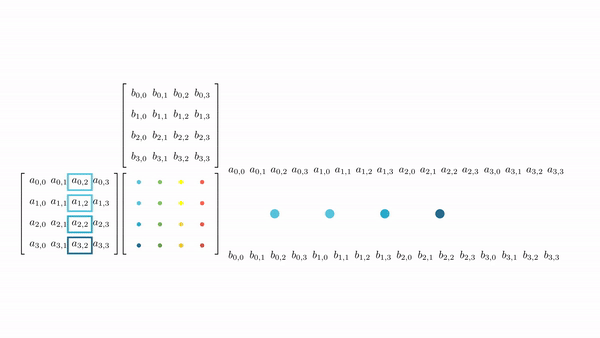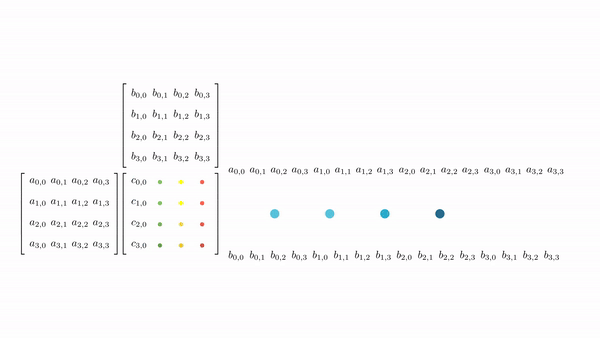
The solution to this problem is very simple. All we need to do is ensure that the threads in a warp are accessing consecutive elements of A. Figure 9 shows thread to element mapping for coalesced memory accesses. In this case, consecutive threads in the warp are responsible for computing elements along the rows of matrix C. This means that each thread accesses the same row of matrix A and consecutive columns of matrix B. For any iteration k, threads in this warp access the consecutive elements of matrix B. That means all the elements will be transferred in parallel at much higher speeds (Figure 10).

Modifying the kernel function is just as simple. All we need to do is change thread-to-element mapping such that thread's x index aligns with the column index of matrix C and y axis with the row index of matrix C.
__global__ void coalesced_mat_mul_kernel(float *d_A_ptr, float *d_B_ptr, float *d_C_ptr, int C_n_rows, int C_n_cols, int A_n_cols)
{
// Working on C[row,col]
const int col = blockDim.x*blockIdx.x + threadIdx.x;
const int row = blockDim.y*blockIdx.y + threadIdx.y;
// Parallel mat mul
if (row < C_n_rows && col < C_n_cols)
{
// Value at C[row,col]
float value = 0;
for (int k = 0; k < A_n_cols; k++)
{
value += d_A_ptr[row*A_n_cols + k] * d_B_ptr[k*C_n_cols + col];
}
// Assigning calculated value (SGEMM is C = α*(A @ B)+β*C and in this repo α=1, β=0)
d_C_ptr[row*C_n_cols + col] = 1*value + 0*d_C_ptr[row*C_n_cols + col];
}
}Benchmark
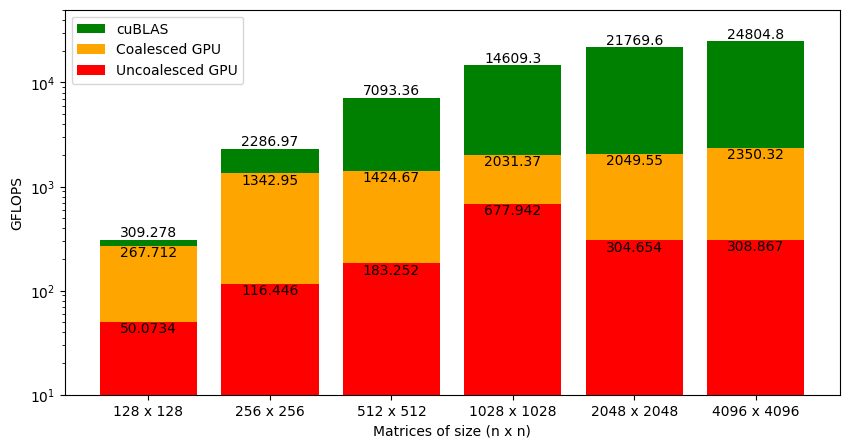
Figure 11 shows the GFLOPS for the coalesced and uncoalesced code against NVIDIA's SGEMM implementation. As we saw earlier that the uncoalesced version was achieving 1% of what cuBLAS can do for large matrices. With coalesced memory accesses, the kernel is at 9% of cuBLAS (which is a big jump from earlier but still not enough). It's interesting to note that our code almost on level with cuBLAS for smaller matrices (i.e. 128 x 128), and the gap widens as the matrix size increases. This is a clue that will help us improve the performance of our code further. But first, let's see what happens if we use Tensor cores instead of CUDA cores.
References
- Coalesced matrix multiplication on a GPU
Header File
Source File
- Benchmarking coalesced matrix multiplication on a GPU