Compiling the code in discussed in Step 5 with flags --ptxas-options=-v outputs that we are using 4096 bytes (4 KB) of shared memory. That's less than the tiled version discussed in Step 4 (which used 8 KB of shared memory). With less shared memory and threads per block, latency tolerance of the kernel is much better. However, we would still like to reduce the global memory accesses by utilizing the shared memory as much as possible. In this post, I will show how we can enable a thread to compute even more elements of the output matrix C and in turn increase the tile sizes of A and B (which will decrease the global memory accesses).
2D Thread Coarsening
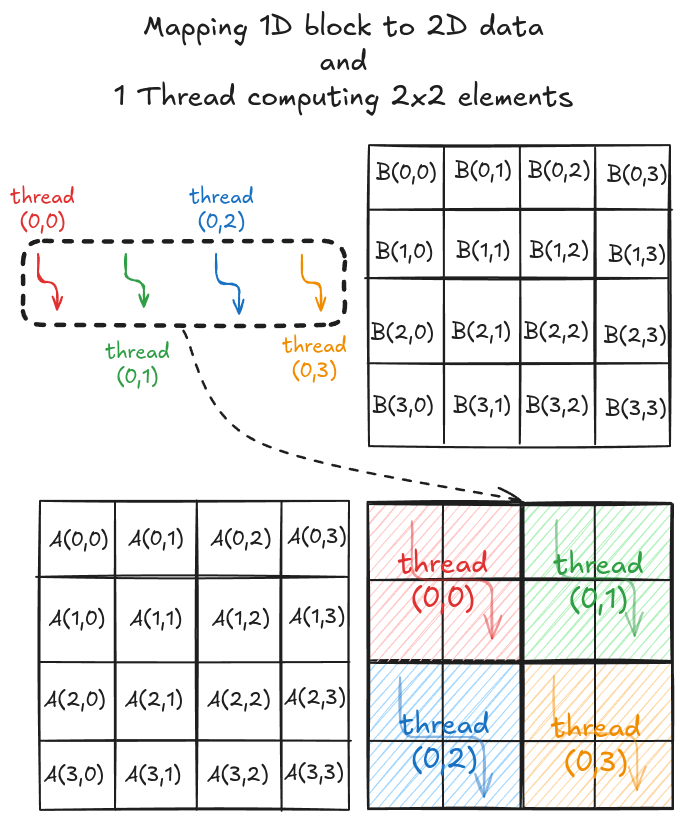
The strategy here is very similar to the one discussed in step 5. The difference here is that a thread computes multiple elements along the row and column of the output matrix C. Consider a simple 4x4 matrix multiplication. To solve this in parallel, let's define a 1x1 grid (i.e., 1 block only) and 1x4 block (i.e., 1D block with 4 threads in x direction). Even though the block is 1D, we can still distribute the threads to cover the 2D space (see Figure 1).
Just as before, we again load tiles of matrix A and B into shared memory (in multiple phases). A tile of A and B is again 4x2 and 2x4 respectively. However, we just have 4 threads this time, so it will take multiple load cycles to fill up the shared memory. Figure 2 shows the load cycles for Phase 0 (the process is same for Phase 1).
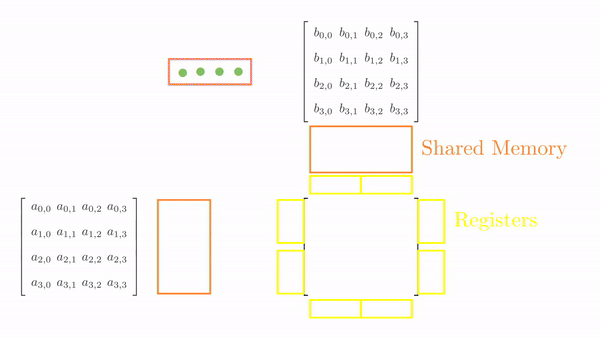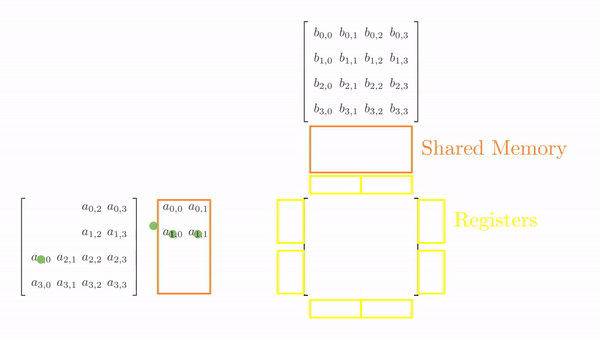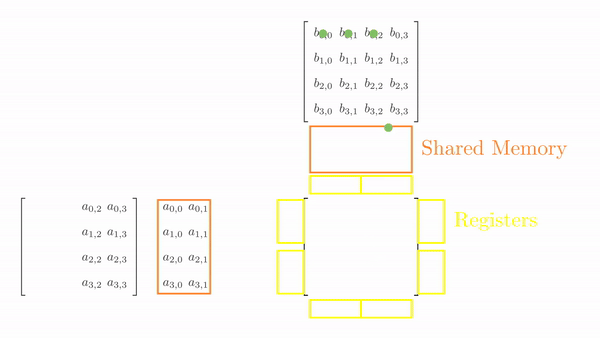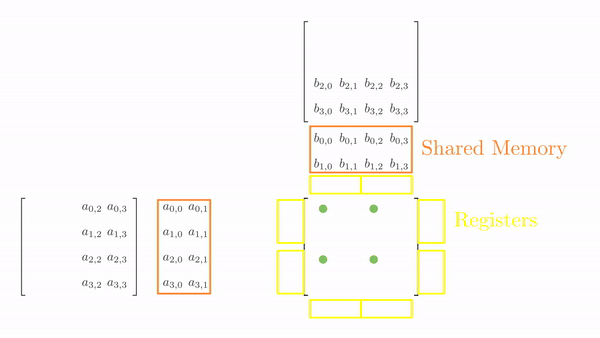
Once the tiles are in the shared memory, the kernel uses registers and stores the elements of both A and B. Instead of just a single element (as seen in step 5), a small vector of A and B are stored in thread register. The loop k inside each each phase is same as before and it decides which row and column vector of A and B respectively will be stored in register. Then a final two nested loops (call this cy and cx) calculates the 4 elements of C assigned to the thread using the required elements of A and B (in short, this is just the vector cross product). Figure 3 shows the complete process for Phase 0.
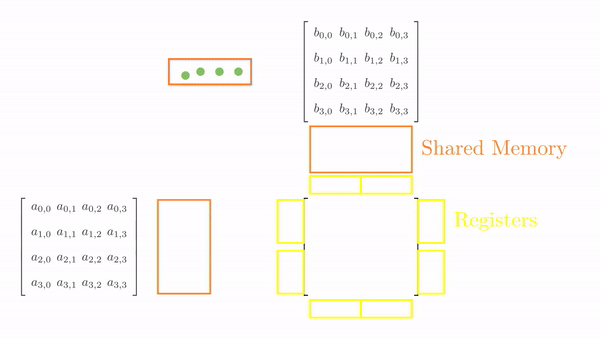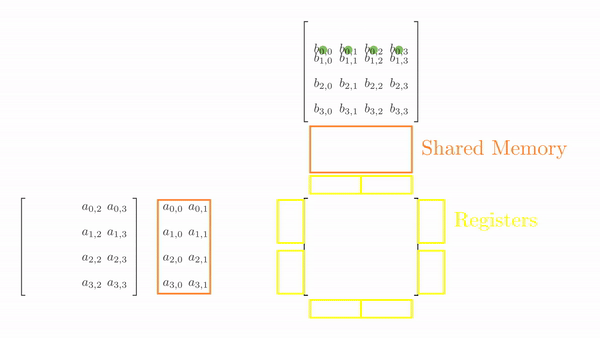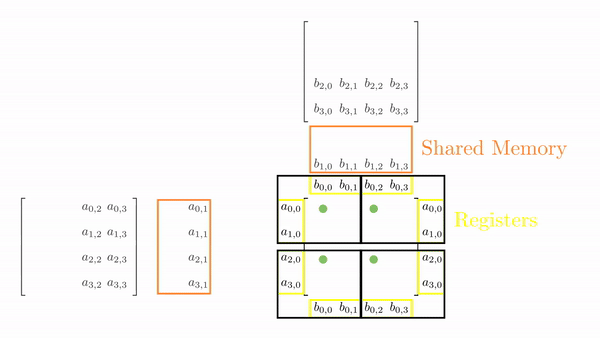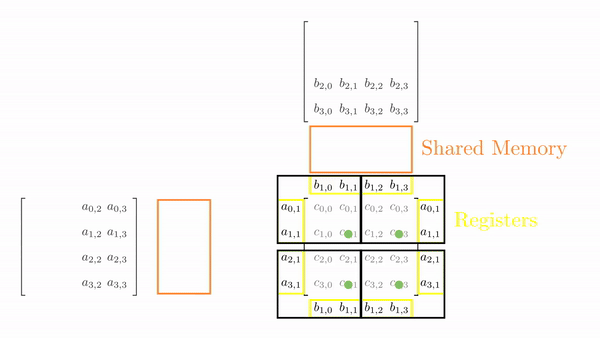
This might look a bit overwhelming, but just consider elements calculated by thread[0,0], i.e., C[0,0], C[1,0], C[0,1] and C[1,1]:
Tiled Version with No Registers
$$C[0,0]= \overbrace{\overbrace{A[0,0] \cdot B[0,0]}^{k_{phase}=0} + \overbrace{A[0,1] \cdot B[1,0]}^{k_{phase}=1}}^{phase=0} + \overbrace{\overbrace{A[0,2] \cdot B[2,0]}^{k_{phase}=0} + \overbrace{A[0,3] \cdot B[3,0]}^{k_{phase}=1}}^{phase=1}$$
$$C[0,1]= \underbrace{\underbrace{A[0,0] \cdot B[0,1]}_{k_{phase}=0} + \underbrace{A[0,1] \cdot B[1,1]}_{k_{phase}=1}}_{phase=0} + \underbrace{\underbrace{A[0,2] \cdot B[2,1]}_{k_{phase}=0} + \underbrace{A[0,3] \cdot B[3,1]}_{k_{phase}=1}}_{phase=1}$$
$$C[1,0]= \underbrace{\underbrace{A[1,0] \cdot B[0,0]}_{k_{phase}=0} + \underbrace{A[1,1] \cdot B[1,0]}_{k_{phase}=1}}_{phase=0} + \underbrace{\underbrace{A[1,2] \cdot B[2,0]}_{k_{phase}=0} + \underbrace{A[1,3] \cdot B[3,0]}_{k_{phase}=1}}_{phase=1}$$
$$C[1,1]= \underbrace{\underbrace{A[1,0] \cdot B[0,1]}_{k_{phase}=0} + \underbrace{A[1,1] \cdot B[1,1]}_{k_{phase}=1}}_{phase=0} + \underbrace{\underbrace{A[1,2] \cdot B[2,1]}_{k_{phase}=0} + \underbrace{A[1,3] \cdot B[3,1]}_{k_{phase}=1}}_{phase=1}$$
Tiled Version with Registers
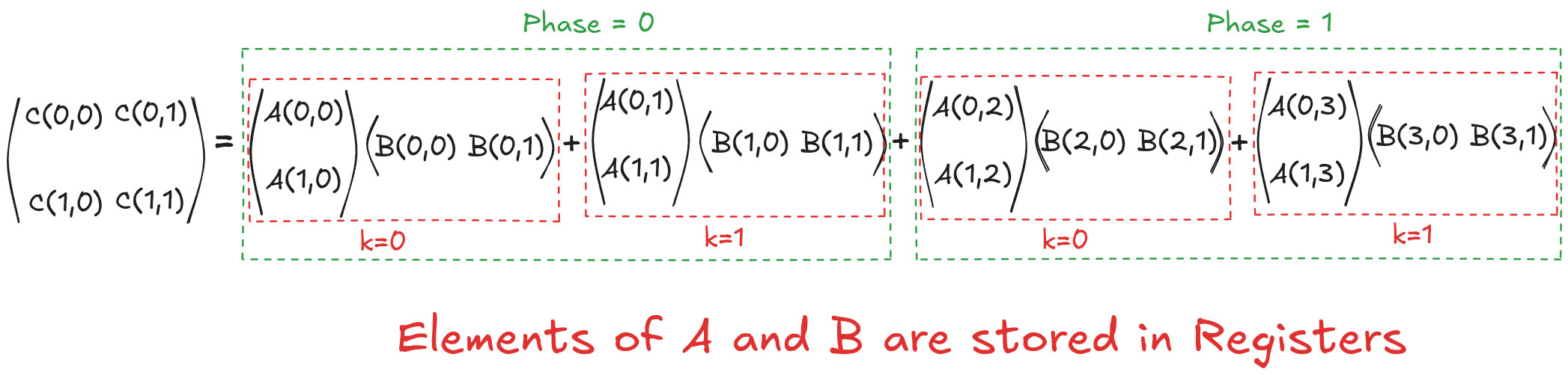
Now, let's put everything we have discussed so far into code for general matrix multiplication. Defining grid and block dimensions again requires careful analysis. We need to tie the tile sizes and the number of elements each thread computes together for compatibility. I decided to go with 128x16 tiles for A and 16x128 tiles for B. Based on this, in my code, each thread computes 8x8 elements.
// Coalescing Factor
#define COARSE_FACTOR_X 8
#define COARSE_FACTOR_Y 8
// Tiles of A
#define tiles_A_rows 128
#define tiles_A_cols 16
// Tiles of B
#define tiles_B_cols 128Each block is responsible for computing a 128x128 tile of output matrix C, and each thread computes 8x8 elements, so we need a total of 256 threads in a block. We can use this to define a grid that spans the whole matrix C.
// Kernel execution
dim3 dim_grid(ceil(C_n_cols/(float)(tiles_B_cols)), ceil(C_n_rows/(float)(tiles_A_rows)));
dim3 dim_block(tiles_A_rows*tiles_B_cols/(COARSE_FACTOR_X*COARSE_FACTOR_Y));
coarse_2d_mat_mul_kernel<<<dim_grid, dim_block>>>(d_A_ptr, d_B_ptr, d_C_ptr, C_n_rows, C_n_cols, A_n_cols);We can now start defining the kernel function. As the block is 1D and threads will get distributed differently (based on what they're doing). We can do the bookkeeping beforehand and allocate the shared memory. We can also initialize the variables that will store small vectors in registers.
__global__ void coarse_2d_mat_mul_kernel(float *d_A_ptr, float *d_B_ptr, float *d_C_ptr, int C_n_rows, int C_n_cols, int A_n_cols)
{
// Number of threads per block
const int n_threads_per_block = tiles_A_rows * tiles_B_cols / (COARSE_FACTOR_X*COARSE_FACTOR_Y);
static_assert(n_threads_per_block % tiles_A_cols == 0);
static_assert(n_threads_per_block % tiles_B_cols == 0);
// Details regarding this thread
const int by = blockIdx.y;
const int bx = blockIdx.x;
const int tx = threadIdx.x;
// 1D -> 2D while loading A
const int A_view_ty = tx / tiles_A_cols;
const int A_view_tx = tx % tiles_A_cols;
const int stride_A = n_threads_per_block/tiles_A_cols;
// 1D -> 2D while loading B
const int B_view_ty = tx / tiles_B_cols;
const int B_view_tx = tx % tiles_B_cols;
const int stride_B = n_threads_per_block/tiles_B_cols;
// Working on C[row, col]
const int row = COARSE_FACTOR_Y * (tx / (tiles_B_cols/COARSE_FACTOR_X));
const int col = COARSE_FACTOR_X * (tx % (tiles_B_cols/COARSE_FACTOR_X));
// Allocating shared memory
__shared__ float sh_A[tiles_A_rows][tiles_A_cols];
__shared__ float sh_B[tiles_A_cols][tiles_B_cols];
// Parallel mat mul
float value[COARSE_FACTOR_Y][COARSE_FACTOR_X] = {0.0f};
float register_A[COARSE_FACTOR_X] = {0.0f};
float register_B[COARSE_FACTOR_Y] = {0.0f};
// .
// .
// .
}Next step is to load the shared memory with tiles of A and B. The thread to element mapping in this case is very similar to before. The only difference is that, we need multiple iterations to load the correct tiles into shared memory.
__global__ void coarse_2d_mat_mul_kernel(float *d_A_ptr, float *d_B_ptr, float *d_C_ptr, int C_n_rows, int C_n_cols, int A_n_cols)
{
// Number of threads per block
const int n_threads_per_block = tiles_A_rows * tiles_B_cols / (COARSE_FACTOR_X*COARSE_FACTOR_Y);
static_assert(n_threads_per_block % tiles_A_cols == 0);
static_assert(n_threads_per_block % tiles_B_cols == 0);
// Details regarding this thread
const int by = blockIdx.y;
const int bx = blockIdx.x;
const int tx = threadIdx.x;
// 1D -> 2D while loading A
const int A_view_ty = tx / tiles_A_cols;
const int A_view_tx = tx % tiles_A_cols;
const int stride_A = n_threads_per_block/tiles_A_cols;
// 1D -> 2D while loading B
const int B_view_ty = tx / tiles_B_cols;
const int B_view_tx = tx % tiles_B_cols;
const int stride_B = n_threads_per_block/tiles_B_cols;
// Working on C[row, col]
const int row = COARSE_FACTOR_Y * (tx / (tiles_B_cols/COARSE_FACTOR_X));
const int col = COARSE_FACTOR_X * (tx % (tiles_B_cols/COARSE_FACTOR_X));
// Allocating shared memory
__shared__ float sh_A[tiles_A_rows][tiles_A_cols];
__shared__ float sh_B[tiles_A_cols][tiles_B_cols];
// Parallel mat mul
float value[COARSE_FACTOR_Y][COARSE_FACTOR_X] = {0.0f};
float register_A[COARSE_FACTOR_X] = {0.0f};
float register_B[COARSE_FACTOR_Y] = {0.0f};
// Phases
const int phases = ceil((float)A_n_cols/tiles_A_cols);
for (int phase = 0; phase < phases; phase++)
{
// Load Tiles into shared memory
for (int load_offset = 0; load_offset < tiles_A_rows; load_offset+=stride_A)
{
if ((by*tiles_A_rows + load_offset+A_view_ty < C_n_rows) && ((phase*tiles_A_cols+A_view_tx) < A_n_cols))
sh_A[load_offset+A_view_ty][A_view_tx] = d_A_ptr[(by*tiles_A_rows+load_offset+A_view_ty)*A_n_cols + (phase*tiles_A_cols+A_view_tx)];
else
sh_A[load_offset+A_view_ty][A_view_tx] = 0.0f;
}
for (int load_offset = 0; load_offset < tiles_A_cols; load_offset+=stride_B)
{
if (((phase*tiles_A_cols + B_view_ty+load_offset) < A_n_cols) && (bx*tiles_B_cols + B_view_tx < C_n_cols))
sh_B[B_view_ty+load_offset][B_view_tx] = d_B_ptr[(phase*tiles_A_cols+B_view_ty+load_offset)*C_n_cols + (bx*tiles_B_cols+B_view_tx)];
else
sh_B[B_view_ty+load_offset][B_view_tx] = 0.0f;
}
__syncthreads();
// .
// .
// .
}
// .
// .
// .
}One the tiles are in shared memory, inside the loop k, we can populate the registers with sub-vectors of A and B. The final step is to perform cross product with these vectors (that is done using loops cx and cy). With all the calculations concluded, we can store the results back in matrix C.
__global__ void coarse_2d_mat_mul_kernel(float *d_A_ptr, float *d_B_ptr, float *d_C_ptr, int C_n_rows, int C_n_cols, int A_n_cols)
{
// Number of threads per block
const int n_threads_per_block = tiles_A_rows * tiles_B_cols / (COARSE_FACTOR_X*COARSE_FACTOR_Y);
static_assert(n_threads_per_block % tiles_A_cols == 0);
static_assert(n_threads_per_block % tiles_B_cols == 0);
// Details regarding this thread
const int by = blockIdx.y;
const int bx = blockIdx.x;
const int tx = threadIdx.x;
// 1D -> 2D while loading A
const int A_view_ty = tx / tiles_A_cols;
const int A_view_tx = tx % tiles_A_cols;
const int stride_A = n_threads_per_block/tiles_A_cols;
// 1D -> 2D while loading B
const int B_view_ty = tx / tiles_B_cols;
const int B_view_tx = tx % tiles_B_cols;
const int stride_B = n_threads_per_block/tiles_B_cols;
// Working on C[row, col]
const int row = COARSE_FACTOR_Y * (tx / (tiles_B_cols/COARSE_FACTOR_X));
const int col = COARSE_FACTOR_X * (tx % (tiles_B_cols/COARSE_FACTOR_X));
// Allocating shared memory
__shared__ float sh_A[tiles_A_rows][tiles_A_cols];
__shared__ float sh_B[tiles_A_cols][tiles_B_cols];
// Parallel mat mul
float value[COARSE_FACTOR_Y][COARSE_FACTOR_X] = {0.0f};
float register_A[COARSE_FACTOR_X] = {0.0f};
float register_B[COARSE_FACTOR_Y] = {0.0f};
// Phases
const int phases = ceil((float)A_n_cols/tiles_A_cols);
for (int phase = 0; phase < phases; phase++)
{
// Load Tiles into shared memory
for (int load_offset = 0; load_offset < tiles_A_rows; load_offset+=stride_A)
{
if ((by*tiles_A_rows + load_offset+A_view_ty < C_n_rows) && ((phase*tiles_A_cols+A_view_tx) < A_n_cols))
sh_A[load_offset+A_view_ty][A_view_tx] = d_A_ptr[(by*tiles_A_rows+load_offset+A_view_ty)*A_n_cols + (phase*tiles_A_cols+A_view_tx)];
else
sh_A[load_offset+A_view_ty][A_view_tx] = 0.0f;
}
for (int load_offset = 0; load_offset < tiles_A_cols; load_offset+=stride_B)
{
if (((phase*tiles_A_cols + B_view_ty+load_offset) < A_n_cols) && (bx*tiles_B_cols + B_view_tx < C_n_cols))
sh_B[B_view_ty+load_offset][B_view_tx] = d_B_ptr[(phase*tiles_A_cols+B_view_ty+load_offset)*C_n_cols + (bx*tiles_B_cols+B_view_tx)];
else
sh_B[B_view_ty+load_offset][B_view_tx] = 0.0f;
}
__syncthreads();
// calculate per-thread results
for (int k = 0; k < tiles_A_cols; ++k)
{
// block into registers
for (int i = 0; i < COARSE_FACTOR_Y; ++i)
register_A[i] = sh_A[row+i][k];
for (int i = 0; i < COARSE_FACTOR_X; ++i)
register_B[i] = sh_B[k][col+i];
for (int cy = 0; cy < COARSE_FACTOR_Y; ++cy)
{
for (int cx = 0; cx < COARSE_FACTOR_X; ++cx)
value[cy][cx] += register_A[cy] * register_B[cx];
}
}
__syncthreads();
}
// Assigning calculated value
for (int cy = 0; cy < COARSE_FACTOR_Y; ++cy)
{
for (int cx = 0; cx < COARSE_FACTOR_X; cx++)
{
if ((by*tiles_A_rows+row+cy < C_n_rows) && (bx*tiles_B_cols+col+cx < C_n_cols))
d_C_ptr[(by*tiles_A_rows+row+cy)*C_n_cols + (bx*tiles_B_cols+col+cx)] = 1*value[cy][cx] + 0*d_C_ptr[(by*tiles_A_rows+row+cy)*C_n_cols + (bx*tiles_B_cols+col+cx)];
}
}
}Benchmark
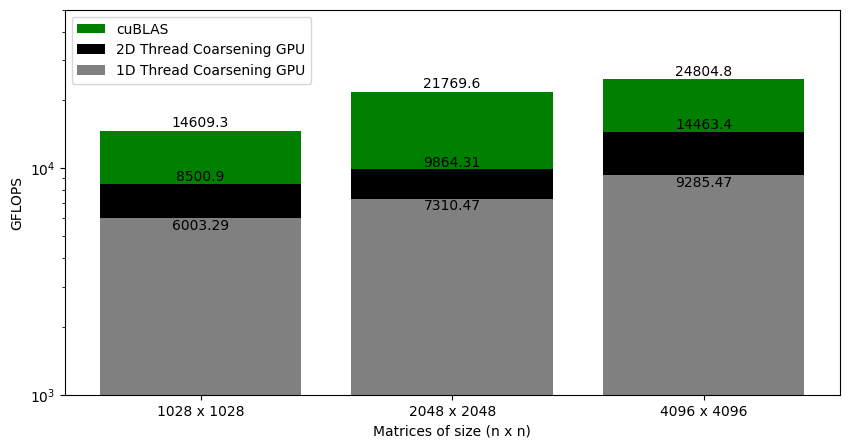
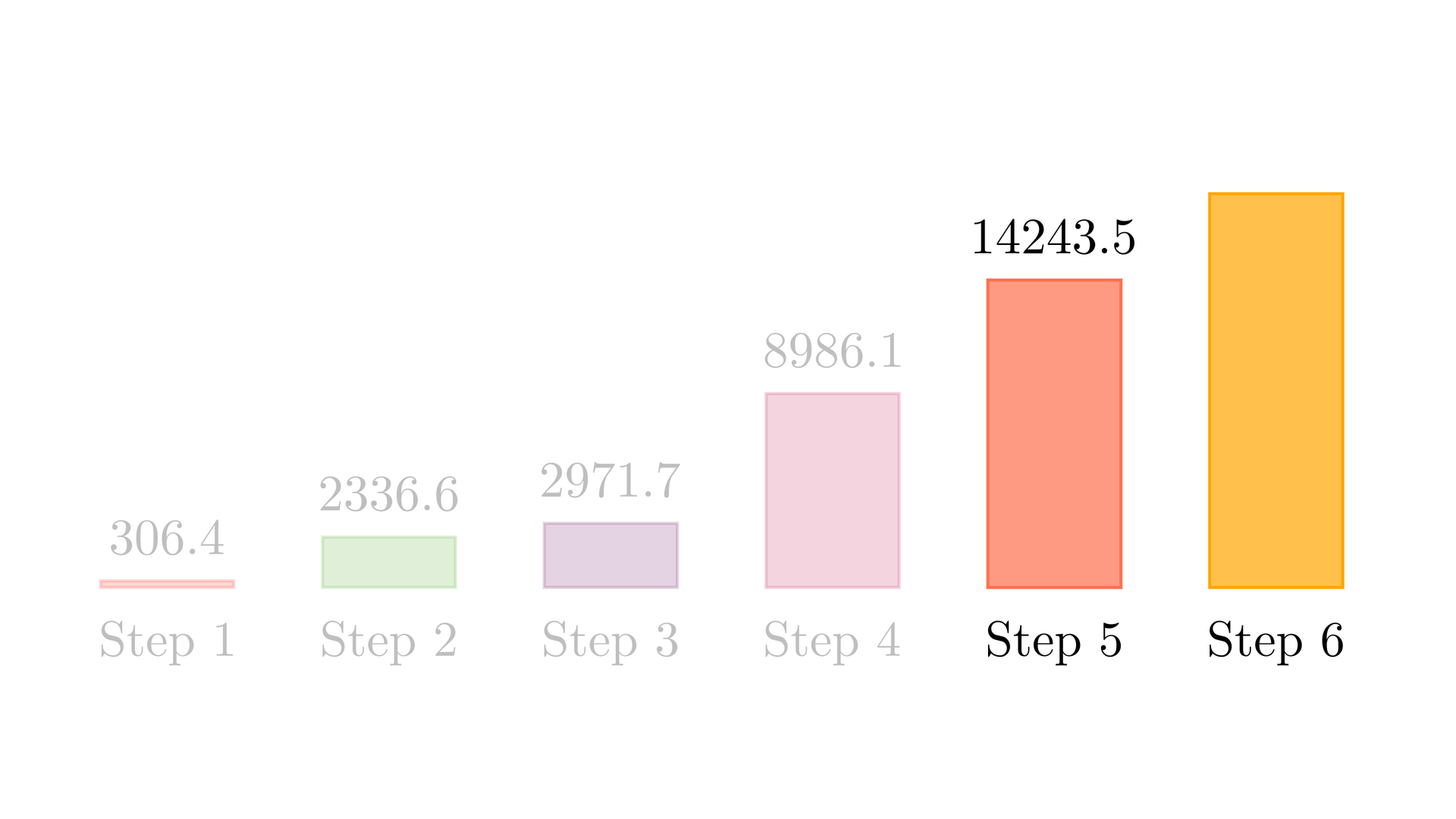
Figure 4 shows the GFLOPS for the 1D and 2D thread coalescing kernel (where each thread computes 8 elements and 8x8 elements respectively) against NVIDIA's SGEMM implementation. As we saw earlier that for the 1D thread coarsening, the kernel was at around 37% of cuBLAS. With 2D thread coarsening, the kernel is now at around 58% of the cuBLAS. This gives another big performance jump.
References
- 2D thread coarsened matrix multiplication
Header File
Source File
- Benchmarking 2D thread coarsened matrix multiplication